MongoDb 学习笔记
早闻大名,开始学习,下面是学习过程留下的笔记,力图用最少的时间,了解 80% 的内容。这个笔记也是以书《MongoDB in Action》为主线来进行,会加一些官网和博客中的内容,这一篇是 Redis 的姊妹篇。
初识
诞生于 2007 年,和 Redis 一样,是为了解决数据结构的自动伸缩问题而产生的,生于云端,专门为 Web 而设计。
关键词:非关系型数据库、直观的数据模型、层次数据结构。
用 C++ 编写,每三个月发布一个主要版本,偶数发型号(第二个数字)是稳定版。
安装&运行
在官网的 downloads 中有很多版本,我们选 Enterprise Server(企业版),因为我们的最终目的是为了用在项目里。需要填一些信息,请放心大胆的填,随便写点什么就能过,也正是因为这样,ssh 无法直接验证成功,所以无法用 wget 来直接下载。
下载完成后我们把压缩包移动到和 Redis 同级目录 /usr/local/ 下,然后解压。运行 MongoDB 还需要一个放数据的目录,默认是 /data/db,我们创建一下:
sudo mkdir -p /data/db
转目录:
cd mongodb-osx-x86_64-enterprise-3.4.10/bin
启动 MongoDB:
./mongod
然后就可以看到重要的启动信息了:
MongoDB starting : pid=15390 port=27017
你可能会遇到这样一个问题,/data/db 这个目录的权限可能无法支持直接写操作,会报这样一个错 Attempted to create a lock file on a read-only directory: /data/db,然后 shutdown,加 sudo 是最简单快捷的处理方式,缺点是每次都要 sudo 然后再输密码,如果只是测试不考虑安全性,比较彻底的方式是改变此目录的权限:chmod 777 data/db。跳过此坑就可以再开一个命令行,转到 mongodb-osx-x86_64-enterprise-3.4.10/bin 下:
// 启动命令行,可以添加环境变量,这样就不用转目录和 ./ 开头了
./mongo
// 获取当前数据库的名称,默认是 test
db.getName()
// 获取全部数据库的名称,
// 默认有 admin local test 三个数据库,
// 其中前两个是系统数据库
show dbs
// 创建users集合,向集合中插入一条document
db.users.insert({"name":"name 1",age:21})
// 查看插入的数据
db.users.find()
// 关闭数据库链接
db.shutdownServer()
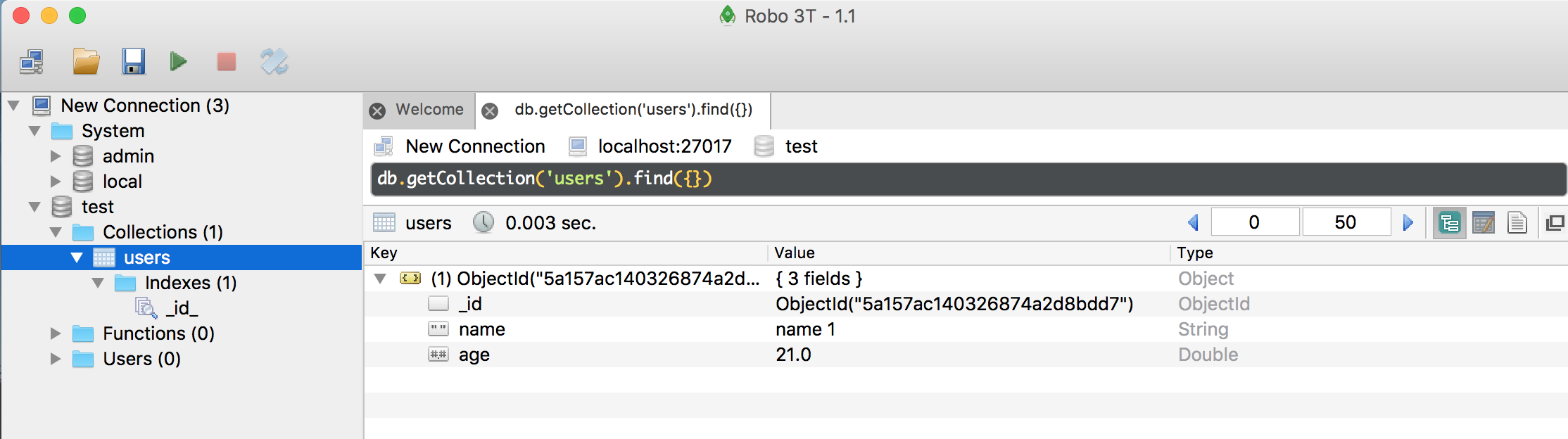
三个数据库中 admin 对应管理员权限,最后的“关闭数据库链接”操作需要切换到 admin 才能进行(use admin)。其中的 mongo 是一个基于 JavaScript 的工具,会加载 Shell 并链接到 mongod 进程,mongod 进程使用一个自定义二进制协议从 Socket 上接收命令。命令行是要学一点的,因为有些机器可能就没有界面,不过有界面的时候也不用难为自己,介绍一个可视化数据库工具:Robo 3T,很方便的就可以链接上,直接上一张图:
主要特性
文档模型
其实就是一个带 id 字段的大 json。数据采用嵌套而非表关联,每个文档能拥有不同的结果,属性可变。
查询
先插入两条数据,下面是示例:
db.articles.insert({
title: 'title1',
author: 'xiaoqiang-zhao',
vote_count: 20,
content: '内容1',
tags: ['tag1', 'tag2', 'tag3'],
comments: [
{
user: 'user1',
text: 'text1'
},
{
user: 'user2',
text: 'text2'
}
]
})
然后看怎么找出来,我们查找 tag 包含 “tag2” 并且 vote_count 大于 10 的文章:
db.articles.find({'tags': 'tag2', 'vote_count': {'$gt': 10}})
你可以变换条件来看看这些查询是否符合你的预期。
速度和持久性
写速度和持久性存在一种相反的关系,数据库设计者需要在速度和持久性中做出权衡。MongoDB 通过控制 Journaling 日志是否开启来控制选择速度和持久性,Journaling 默认是开启的。
分布式
不需要编写应用层代码就能实现集群,主从互备和容灾都可以底层本实现。
增删改查 和 索引
切库
切换数据库,数据库不用刻意新建,切换的时候如果没有就直接创建一个:
use mydb
插入数据
文档也是同样,向文档中插入数据,如果文档还不存在就直接创建一个:
db.users.insert({name: 'jack'})
// 插入一个稍微复杂一点的,方便后面查询
db.users.insert({
name: 'tony',
age: 18,
favorites: {
movies: ['Game of Thrones'],
sports: ['football']
}
})
查询数据
查询的姿势比较多,我们先开个头:
// 最简单的查文档全集
db.users.find()
// 查单一字段
db.users.find({name: 'tony'})
// 内嵌文档单一字段
db.users.find({'favorites.movies': 'Game of Thrones'})
对于数字的查询会用到一些比较符号:
- (>) 大于 - $gt;
- (<) 小于 - $lt;
- (>=) 大于等于 - $gte;
- (<= ) 小于等于 - $lte;
比如我们查找成年用户(大于等于 18 岁):
db.users.find({age: {
'$gte': 18
}})
对于字符串,没有像 like 这样的语句,而是直接上正则,比如我们要找 name 以 t 开头的人:
db.users.find({
name: /^t/i
})
还有一个比较特殊的地方就是数组的搜索,上面用到的 db.users.find({'favorites.movies': 'Game of Thrones'}) 是包含某一项,精确包含且只包含某一项或几项用下面命名:
// 先插入一条数据
db.users.insert({
name: 'tony',
age: 18,
favorites: {
movies: ['Game of Thrones', 'The hundred'],
sports: ['football']
}
})
// 精确查询
db.users.find({'favorites.movies': ['Game of Thrones']})
范围条件任意元素匹配查询
// 先插入一条数据,
// 其中 scores 表示其中成绩和期末成绩
db.users.insert({
name: 'tony',
age: 18,
scores: [59, 90],
favorites: {
movies: ['Game of Thrones', 'The hundred'],
sports: ['football']
}
})
// 有没有不及格的
db.users.find({'scores': {'$lt': 60}})
嵌套文档查询,比如有没有不及格的科目,直接用数组的键值就可以:
// 先准备数据
db.users.insert({
name: 'tony',
age: 18,
courses: [
{
name: 'mathematics',
score: 59
},
{
name: 'material',
score: 90
}
],
favorites: {
movies: ['Game of Thrones', 'The hundred'],
sports: ['football']
}
})
// 查询
db.users.find({'courses.score': {'$lt': 60}})
另外还有 $elemMatch、$all、$size 等关键字就不一一讲了,参见这篇博文:http://blog.csdn.net/leshami/article/details/55049891 。
更新数据
更新操作前半段是查询,后半段是更新,还有一点需要注意,MongoDB 的更新操作默认只会应用于匹配到的第一个文档,如果希望操作应用于匹配到的搜有文档,需要加参数。先看个简单的:
// 将 name 为 neo 的用户年龄设置成 19
db.users.update({name: 'neo'}, {$set: {age: 19}})
// neo 喜欢的电影应该包括 The Matrix(黑客帝国)
db.users.update({name: 'neo'}, {$addToSet: {'favorites.movies': 'The Matrix'}})
$set 可以直接设置值;$addToSet 可以像数组中添加元素,并且保证不重复添加,与之类似的还有 $push,直接添加不判断是否重复;如果我们想删除某个字段,可以用 $unset 来做,需要注意的是被删除的字段需要写成键值对的形式,值是啥无所谓:
db.users.update({name: 'neo'}, {$unset: {'age': 0}})
// 下面这样是不行滴
db.users.update({name: 'neo'}, {$unset: 'age'})
当然还有其他的内容,这里就不一一列举了。
删除数据
删除数据是删除一条或多条完整的数据,上面的 $unset 是删除一条数据的某属性,这里可以复用搜索条件,简单理解就是查到什么删什么,比如我们要把 neo 删掉:
db.users.remove({name: 'neo'})
如果不加条件会删除集合里面的全部数据,还有一个操作是 drop,可以用来删除集合和集合上的全部索引,drop 函数不带参数:
db.users.drop()
索引
索引是用来提升查询速度的,在没有索引的时候我们要查一个集合需要遍历搜有元素,索引的作用是把所有元素先按照索引的规则排序,然后查的时候用二分法(多数数据库是这么干的,MongoDB也不例外)就快多了。索引在比较多的数据下才会起显著作用,我们先插入 20 万条数据,猜猜要用多长时间?
for (i = 0; i < 200000; i++) {
db.t1.insert({number: i})
}
// 可以验证一下是不是插入了 20 万条
db.t1.count()
大约用了 59秒,查询任意一条大约需要 90 毫秒,通过 explain('executionStats') 可以查看查询的一些细节,比如在 executionStats 下,executionTimeMillis 是查询时间、totalDocsExamined 是扫描了多少文档、totalKeysExamined 索引扫描了多少文档。
db.t1.find({number: 999}).explain('executionStats')
查看当前集合上有什么索引,id 是默认存在的索引:
db.t1.getIndexes()
我们加一个对 number 的索引试试,对 number 字段建立正序索引:
db.t1.ensureIndex({number: 1})
再执行上面命令就可以看到多了一个索引,再执行查询的时候发现查询时间下降到了 2 毫秒。
基本管理
先整理一下我们前面用过的一些管理命令:
// 启动数据库服务,可以带路径
mongod -dbpath /data2/db
// 显示系统上的数据库列表
show dbs
// 获取当前数据库名称
db.getName()
// 切换数据库
use test
// 查看数据库中的集合
show collections
// 关闭数据库链接
db.shutdownServer()
还有一些其他的常用命令:
// 获取当前数据库信息
db.stats()
// 获取某集合的信息
db.numbers.stats()
// 持续添加中...
db 下还有很多方法,执行 db.help() 可以看到,粘贴前几个进来看看:
db.adminCommand(nameOrDocument) - switches to 'admin' db, and runs command [ just calls db.runCommand(...) ]
db.auth(username, password)
db.cloneDatabase(fromhost)
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb, todb, fromhost)
db.createCollection(name, { size : ..., capped : ..., max : ... } )
同样,集合的方法也可以通过 db.t1.help() 拿到:
db.t1.find().help() - show DBCursor help
db.t1.bulkWrite( operations, <optional params> ) - bulk execute write operations, optional parameters are: w, wtimeout, j
db.t1.count( query = {}, <optional params> ) - count the number of documents that matches the query, optional parameters are: limit, skip, hint, maxTimeMS
如果你想查看某个方法的源码,那么去掉括号就是了:
db.t1.find
// 下面是 find 方法的实现
function (query, fields, limit, skip, batchSize, options) {
var cursor = new DBQuery(this._mongo,
this._db,
this,
this._fullName,
this._massageObject(query),
fields,
limit,
skip,
batchSize,
options || this.getQueryOptions());
var connObj = this.getMongo();
var readPrefMode = connObj.getReadPrefMode();
if (readPrefMode != null) {
cursor.readPref(readPrefMode, connObj.getReadPrefTagSet());
}
var rc = connObj.getReadConcern();
if (rc) {
cursor.readConcern(rc);
}
return cursor;
}
用在项目中
概述
MongoDB 为各种语言提供了驱动,Node.js 的话首选 mongoose。mongoose 是 NodeJS 的驱动,不能作为其他语言的驱动。Mongoose有两个特点:
- 1、通过关系型数据库的思想来设计非关系型数据库;
- 2、基于mongodb驱动,简化操作。
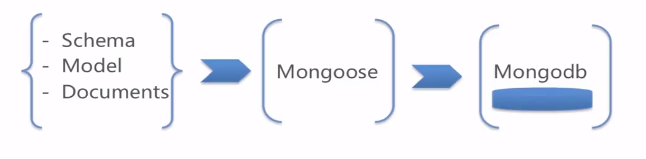
mongooose中,有三个比较重要的概念,分别是 Schema、Model、Entity。它们的关系是:Schema 生成 Model,Model 实例化 Entity。Schema 主要用于定义 MongoDB 中Collection 里 document 的结构。比较清晰的写法像下面这样:
var Schema = mongoose.Schema;
const userSchema = new Schema({
name: String
});
const User = mongoose.model('users', userSchema);
还有一个简化写法:
const User = mongoose.model('users', {
name: String
});
model 方法将 Schema 编译为 Model,model 方法的第一个参数决定 Collection 的名称系,规则是这样的:
- 如果不以数字和"s"结尾,全部转换为小写然后加 "s";
- 如果以数字和"s"结尾,直接作为 Collection 的名称。
Connect - 数据库连接
首先需要安装:
npm install mongoose
其次我们要执行 mongod 命令把 MongoDB 启动起来,然后 Node.js 的连接代码是这样:
const mongoose = require('mongoose');
mongoose.Promise = require('bluebird');
mongoose.connect('mongodb://127.0.0.1/mydb', {
useMongoClient: true
}).then(() => {
console.log('数据库链接成功');
}, err => {
console.log('数据库链接失败:', err);
});
我这里用的东西全是目前(2017.12.9)的最新版,MongoDB 3.6,mongoose 4.13,node 8.9,之所以写这些是因为“有坑!”。在官方文档中 127.0.0.1 位置放的是 localhost,这居然是 Node.js 的 bug。然后是 Promise,最新版的 mongoose 将 Promise 进行了抽离,如果不单独处理会有 Warning。
在测试的时候可以跑完代码就断开数据库连接:
// 断开数据库链接
setTimeout(() => {
mongoose.disconnect(function(){
console.log("断开连接");
})
}, 2000);
下面按照惯例我们来写一遍 CRUD。
Create
var User = mongoose.model('User', {
name: String
});
var user = new User({
name: 'aaa'
});
user.save().then(() => {
console.log('user 保存成功');
}, res => {
console.log('user 保存失败:', err);
});
上面是用 Promise 来写的,也可以用回调来写,下面的查询我们就用回调来写。
Retrieve
查找数据:
// 找出 users collections 中的所有数据
User.find((err, docs) => {
console.log('users all:');
console.log(docs);
});
// 找出 users collections 中 name 为 aaa 的所有数据
User.find({
name: 'aaa'
}, (err, docs) => {
console.log('users of name is "aaa":');
console.log(docs);
}).sort({
// 倒序: -1, 正序: 1
KEY: -1
});
Update
我们将 name 为 "ccc" 的用户换个名字:
User.update({
name: 'ccc'
}, {
name: 'bbb'
}).then();
[注意]使用 update 方法的时候,如果是回调形式,那么回调函数不能省略,如果是 Promise 形式,那么 then() 不能省略,否则数据不会被更新。如果回调函数里并没有什么有用的信息,则可以使用 exec() 简化代码:
User.update({
name: 'bbb'
}, {
name: 'ccc'
}).exec();
Delete
User.remove({
name: 'aaa'
}).exec();
[注意]文档的 remove 方法的回调函数不能省略,否则数据不会被删除,同上。
后台启动
在 package.json 中配置脚本:
"scripts": {
"db": "sudo mongod --config ./mongod.conf"
},
mongod.conf 文件配置内容:
port=27017
dbpath=/data/db
logpath=./logs/mongodb.log
logappend=true
fork=true
启动数据库的时候执行 npm run db。
一种实践方式
数据处理写在一起可能会比较大,一般都采用分层的方式来处理,虽然写着有些繁琐,但是由于各层分工明确易于维护,这里介绍一种分层方式,这种分层方式参考了 Node.js 中文论坛的实现。
首先是 models 层,负责数据库的链接、数据定义、集中对外输出。
待续...
附注
Community Server, 社区版,比企业版少一些高级功能
Enterprise Server, 企业版,功能最全,免费